케라스에서 딥러닝을 하는 과정은 아래와 같습니다.

01. 문제정의
여기서 실습할 AND Function은 AND Gate의 역할을 하는 1의 값이 나오게 만드는 딥러닝을 해 보는 것이다.

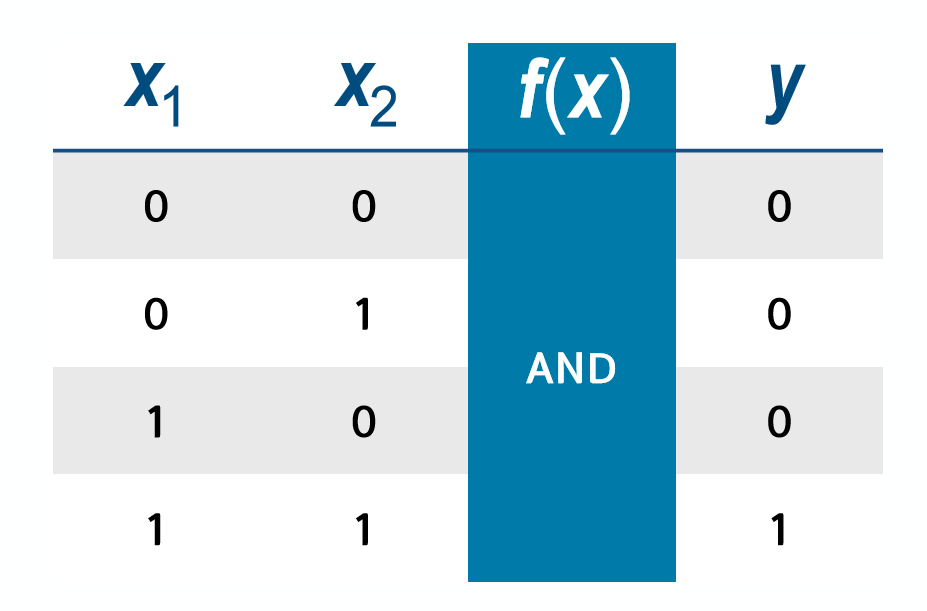
02. 데이터셋 준비
#1. Numpy 가져오기
import numpy as np
print(np.__version__)
#2. 입력/출력 데이터 만들기
X = np.array([[0,0], [1,0], [0,1], [1,1]])
y = np.array([[0], [0], [0], [1]])먼저 input output의 데이터 셋을 위해서 numpy를 import합니다. numpy는 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리 할 수 있도록지원하는 파이썬의 라이브러리입니다.
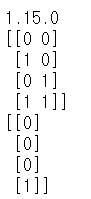
03. 모델 설정
# 3. Keras 패키지 가져오기
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation
print(keras.__version__)
# 4. MLP 모델 생성
model = Sequential()
# 4=노드 갯수, input_dim=feature 갯수
# model.add(Dense(2, input_dim=2))
# model.add(Activation('relu'))
model.add(Dense(10, input_dim=2, activation='relu'))
# model.add(Dense(1))
# linear=특정값예측, sigmoid=이진클래스에측, softmax=다중클래스예측
# model.add(Activation('sigmoid'))
model.add(Dense(1, activation='sigmoid'))
print(model.summary())모델은 사람 레고블럭의 인형과 같습니다. 여기서 먼저 Sequential 라이브러리를 import한 다음에 모델, 설계도를 먼저 생성합니다. 그리고 네트워크를 만드는데 Dense를 통해 먼저 하나의 Perceptron을 생성합니다. 첫번째 인자값은 만들 출력 노드의 개수입니다. 두번째 input_dim은 입력 값을 의미합니다. 세번째는 출력의 형태를 어떤 방식으로 할 것인가 입니다.
model.add(Dense(10, input_dim=2, activation='relu')를 해석하면 2개에 관해서 10개의 출력이 나오는데 actiavation함수가 relu이므로 0에서 1의 값을 갖는 형태로 출력되게 됩니다.

실제로 python을 실행해 보면 param이 나오는데, 출력이 10개인데 param이 30인 이유는, input값 2개에 b 1개가 포함된 3개의 param이 각각 10개의 출력에 대해 weight를 조정하기 때문에 Param이 30이 되게 됩니다.
이제 네트워크 머리층을 만들었으므로, 몸통과 최적화를 설정해준 뒤에 컴파일 해줍니다. 몸통은 objective로 cost function을 어떻게 설정할 것인가의 문제입니다.
mean_squared_error 특정한 값을 예측할 때, 여러 함수 중 하나를 선택하는 classification를 쓰고, 이진분류를 할 때는binary_crossentropy를 쓰는데, 여기서는 출력값이 0과 1중 하나니깐 binary_corssentropy를 쓰고, 최적화는 일반적인 sgd를 쓰고 컴파일을 합니다.
# 5. Compile - Optimizer, Loss function 설정
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
04. 모델 훈련/평가
여기까지 모델을 완성하였으면, 이제는 모델이 정확히 작동하는지 러닝해봅니다.
# 6. 학습시키기
batch_size = 1
epochs = 10000
model.fit(X, y, epochs=epochs, batch_size=batch_size, shuffle=True, verbose=1)
# 7. 모델 테스트하기
predict = model.predict(np.array([[1,1],]))
print(predict)여기서 X는 입력값, y는 테스트한 결과값입니다. batch_size는 몇 개의 샘플로 가중치를 갱신할 것인지 결정하는 것입니다. 예를 들어 시험을 볼 때 1문제 풀고 1문제 답보고 하면 batch_size는 1이고, 100문제 보고 100문제 답을 보면 batch_size는 100이 됩니다. 배치사이즈가 작을수록 가중치 갱신이 자주 일어납니다.
epchos에포크를 비유하면 모의고사를 몇 번 풀어볼까이다. 100문항의 문제들을 반복해서 푸는 것이다.
shuffle은 문제를 풀 때마다 셔플로 돌린다는 것이고, verbose는 시각화해서 보이게 한다는 뜻이다.
model.fit(X, y, epchos=epochs, batch_size=batch_size, suffle=True, verbose=1)

'프로그래밍 일반 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 케라스실습 03. 당뇨병 (0) | 2019.11.25 |
|---|---|
| [딥러닝] 케라스실습 02. XOR Function (0) | 2019.11.25 |
| [딥러닝] 케라스의 기초 개념 (0) | 2019.11.25 |
| [딥러닝] 3. 딥러닝시 주의할 점 (0) | 2019.11.25 |
| [딥러닝] 2. 딥러닝의 동작과정 (0) | 2019.11.25 |



