01. 문제정의
피그마 인디언 당뇨병 발병 데이터를 딥러닝 해보고 당뇨병을 예측하는 모델입니다.
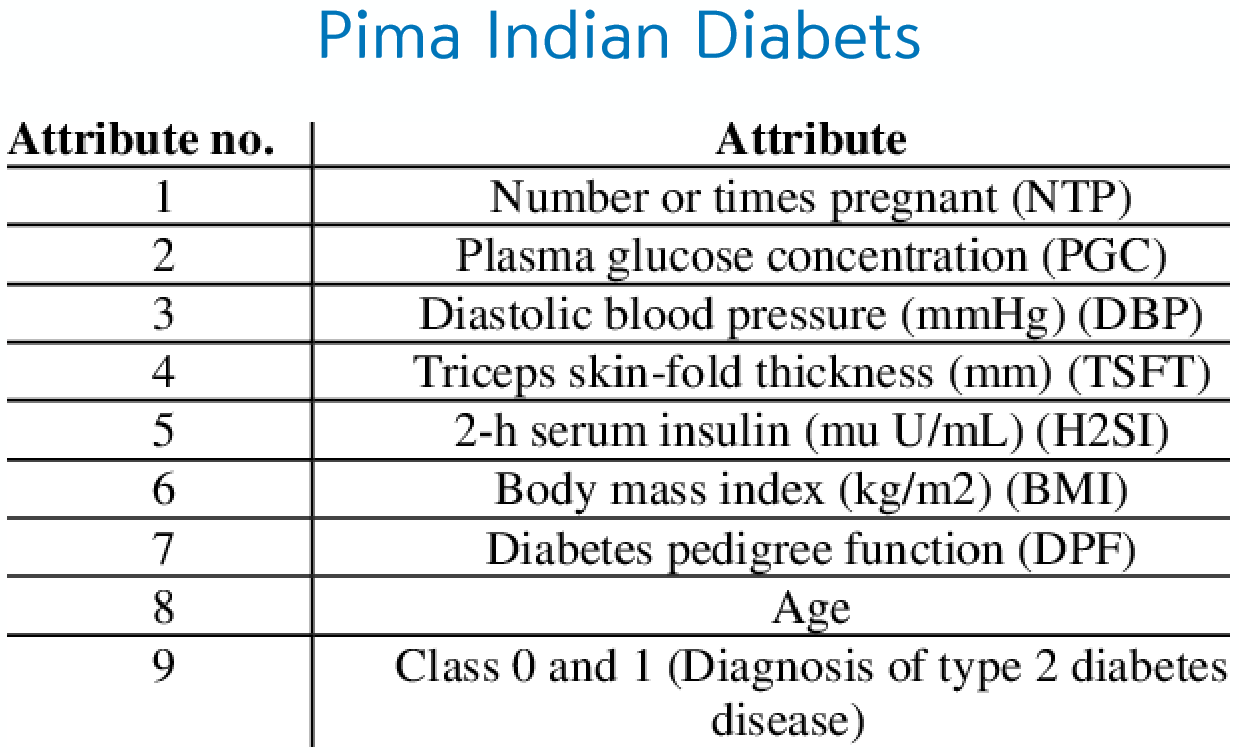
02. 데이터셋 불러오기
# 1. Pandas 가져오기
import pandas as pd
print(pd.__version__)
# 2. 데이터 불러오기
dataset = pd.read_csv('diabetes_data.csv')
dataset.head(10)
# 3. X/y 나누기
X = dataset.iloc[:,:-1]
y = dataset.iloc[:,-1]
print(X.shape)
print(y.shape)
# 4. Train set, Test set 나누기
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=9)
X_val,X_test,y_val,y_test = train_test_split(X_test, y_test, test_size=0.5, random_state=123)
print(X_train.shape)
print(y_train.shape)
print(X_val.shape)
print(y_val.shape)
print(X_test.shape)
print(y_test.shape)
컴퓨터 프로그래밍에서 pandas는 데이터 조작 및 분석을 위해 Python 프로그래밍 언어로 작성된 소프트웨어 라이브러리입니다. 특히, 숫자 테이블 및 시계열 조작을위한 데이터 구조 및 조작을 제공합니다
pandas에서 dataset을 설명하면 dataset.iloc[ : ]
iloc 인덱서는 loc 인덱서와 반대로 라벨이 아니라 순서를 나타내는 정수(integer) 인덱스만 받는다. 다른 사항은 loc 인덱서와 같다. loc는 location을 의미하며 [ 행 인덱스 열 인덱스]를 의미한다.
[ : , :-1]은 행 전체를 의미하고, 열은 전체에서 -1을 뺀 값을 의미한다.
[ : , -1]은 앞은 행 전체, 뒤에는 열에서 -1만을 의미한다.
# 5. Keras 패키지 가져오기
from keras.models import Sequential
from keras.layers import Dense, Dropout
import keras
print(keras.__version__)
# 6. MLP 모델 생성
model = Sequential()
model.add(Dense(20, input_dim=8, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(8, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
print(model.summary())
# 7. Compile - Optimizer, Loss function 설정
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])여기서는 Perceptron을 2개의 층으로 생성했다. Dropout은 그냥 중간에 섞으면 된다. 그러면 랜덤하게 학습할 때마다 석게 된다.
# 6. 학습시키기
batch_size = 16
epochs = 1000
history = model.fit(X, y, epochs=epochs,
batch_size=batch_size,
validation_data=(X_val, y_val), shuffle=True, verbose=1)
# 7. 모델 평가하기
train_accuracy = model.evaluate(X_train, y_train)
test_accuracy = model.evaluate(X_test, y_test)
print(train_accuracy)
print(test_accuracy)이전 코드와 다른 것이 있다면 validation_data를 섞은 것이다. 그냥 fit에 인자값으로 넣어주면 된다.
# 10. 학습 시각화하기
import matplotlib.pyplot as plt
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Accuracy')
plt.ylabel('epoch')
plt.xlabel('accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Loss')
plt.ylabel('epoch')
plt.xlabel('loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 6. EarlyStopping(최적의 로스일때 정지)
batch_size = 16
epochs = 1000
history = model.fit(X, y, epochs=epochs, batch_size=batch_size, validation_data=(X_val, y_val), shuffle=True, verbose=1)
# 모델 저장
model_path = 'model.h5'
model.save(model_path)
from keras.models import load_model
loaded_model = load_model(model_path)
print(load_model.summary())'프로그래밍 일반 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 이미지 분류 이론 (0) | 2019.11.25 |
|---|---|
| 딥러닝 교재 (0) | 2019.11.25 |
| [딥러닝] 케라스실습 02. XOR Function (0) | 2019.11.25 |
| [딥러닝] 케라스 실습 01. AND Function 문제 (0) | 2019.11.25 |
| [딥러닝] 케라스의 기초 개념 (0) | 2019.11.25 |


