딥러닝을 할 당시에 사람은 물체를 그림으로 보지만, 컴퓨터는 모든지 숫자로만 이해한다. 이미지를 줘도 숫자로만 확인된다. 이런 문제를 어떻게 해결할 것인지가 중요하게 된다.

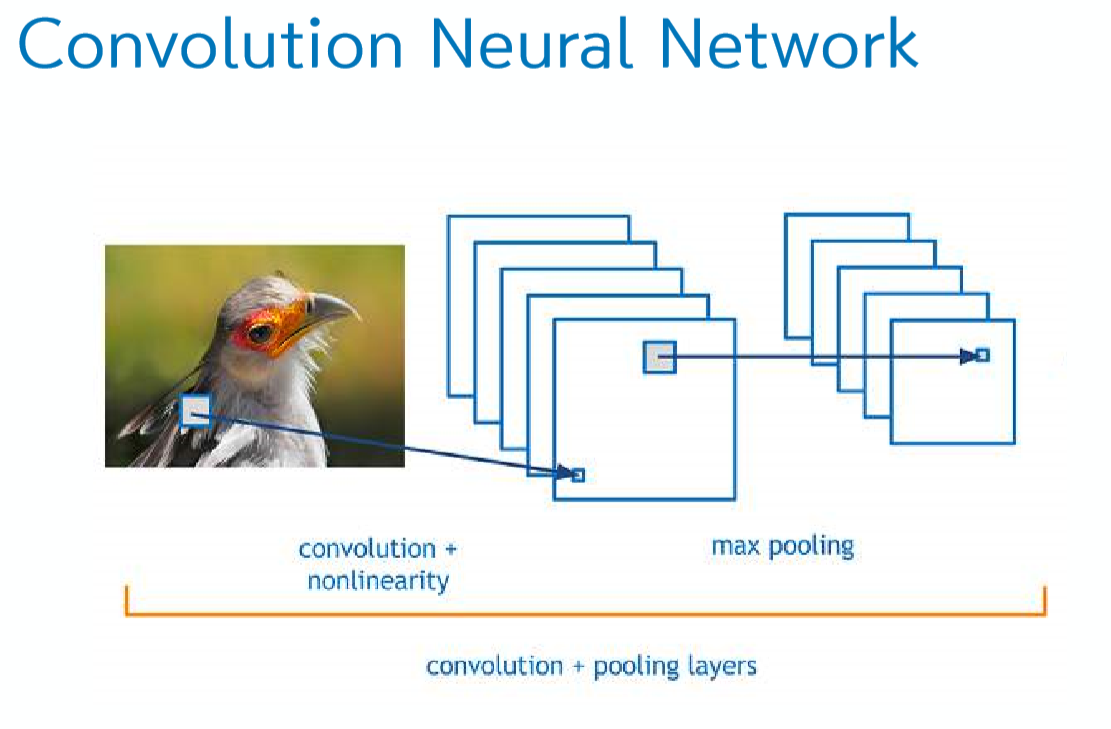
MLP는 사람의 뇌를 본 따서 만든 것이다. 뉴런처럼 만든것이다. 사람이 무엇인가를 보게한다? 사람이 무엇인가를 인식하고 보는 시스템을 비슷하게 만들면 컴퓨터도 무엇인가를 볼 수 있지 않을까? Convolutional Neural Network가 나오면서 이미지 분석, 음성인식 문제들이 해결되었다. Convolutional Neural Network에서는, 뇌에서는 하나의 이미지를 볼 때 새라고 한 번에 인식하는 것이 아니라 부분적으로 쪼개서 보게 된다. 마찬가지로 이미지를 여러개로 쪼갤 수 있게 된다.

01. Convolution Layer
Convolution은 합성곱으로 아래와 같이 matrix를 곱해서 새로운 matrix를 곱하는 것이다.
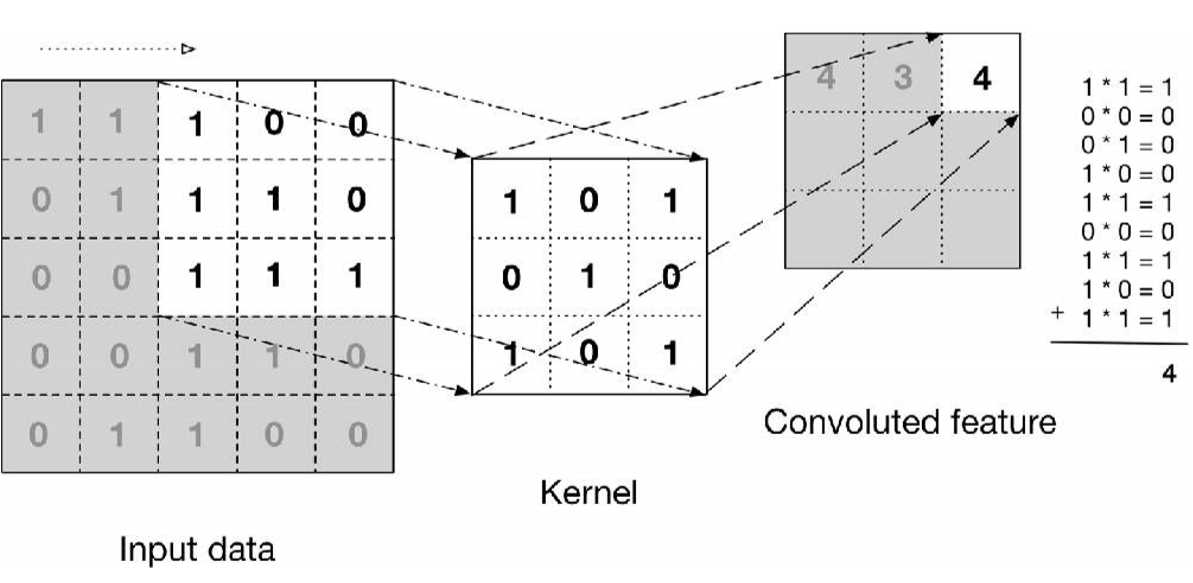

Convolution - filter
이렇게 Convolution 한 번 한 것이 사진 한장이고. 여러 번 하면 filter가 여러장 생기게 된다. filter은 한 장에 가중치가 들어가 있게 된다. 몇장의 사진을 뽑아낼 것인가. 필터를 쉽게 이해하려면 사진을 찍은 뒤에 사진기 필터창에 보면 밝음, 없음, 그레이 등등으로 보여지는데 이것이 필터이다. 아래에서 필터는 9장이다.

Convolution - Padding
한 번의 Convolution을 하게 되면 사진이 축소되고, 2번 3번하게 되면 본래의 사진을 알아볼 수 없게 된다. 따라서 Padding이라는 개념으로 사진의 특징을 추출하게 만드는 것이 필요하다.

여기까지의 동작을 전체적인 그림과 코드로 보면 아래와 같다.
Conv2D(32, (5, 5), padding='valid', input_shape=(28, 28, 1), activation='relu')코드를 해석해보면 이미지를 추출해낼 때, 5*5의 칸으로 추출하며, 32장의 filter를 뽑아낸다. padding은 그림이 너무 작아지는 것을 방지하는 것인데 여기서는 valid를 썼다. same을 쓰면 padding값을 줘서 정보 손실을 방지하게 된다.
input_shape=(28, 28, 1)은 28*28사이즈의 1인 0 1로 표현되는 사진 한 장을 넣겠다는 것이다. 만약 28*28*3이라면 3장을 넣고 보통 RGB를 쓸 때 많이 쓰인다.
02. MaxPooling
MaxPooing은 압축과도 같은 것이다. 기존의 사진을 그대로 쓰면 용량이 너무 커지기 때문에 압축을 해야 컴퓨터가 효율적으로 동작할 수 있게 된다. 마치 사람을 인식할 때 눈, 코, 입의 위치가 조금씩 달라도 사람이라고 인식하는 것과 같다.

코드는 아래와 같다.
MaxPooling2D(pool_size=(2,2))pool_size는 수직, 수평 축소 비율을 지정한다. (2,2)라면 본래 사진이 4*4였떤 것을의 크기의 반을 줄여준다.
03. Flatten
그런 다음에 Flatten()의 과정이 필요하다. MLP로 학습을 시키기 위해서는 1차원이여야 하기 때문이다.

현재 주어진 사진의 값은 2차원이기 때문에 Flatten()을 통해 1차원으로 만들어야 학습이 된다.
Flatten()
전체적으로 돌아가는 그림을 보면 아래와 같다.

'프로그래밍 일반 > 딥러닝' 카테고리의 다른 글
| 딥러닝 교재 (0) | 2019.11.25 |
|---|---|
| [딥러닝] 케라스실습 03. 당뇨병 (0) | 2019.11.25 |
| [딥러닝] 케라스실습 02. XOR Function (0) | 2019.11.25 |
| [딥러닝] 케라스 실습 01. AND Function 문제 (0) | 2019.11.25 |
| [딥러닝] 케라스의 기초 개념 (0) | 2019.11.25 |


